BlueAdmiral.com
|
BlueAdmiral.com |
|
| Neural Networks |
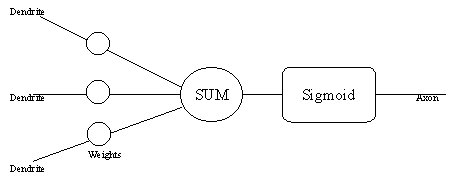
| Introduction First of all, when we are talking about a neural network, it would be better to say "artificial neural network" (ANN), because that is what we mean most of the time. Biological neural networks are much more complicated in their elementary structures than the mathematical models we use for ANNs. The conventional (Von Neumann) model of computing is to use a single but powerful processor with external memory. The neural model is to use a network of many very simple processing elements (PEs) called neurons, each possibly having a (small amount of) local memory. The PEs are connected by unidirectional communication channels (connections or synapses), that carry numeric (as opposed to symbolic) data. The units operate only on their local data and on the inputs they receive via the connections. The diagram below shows the implementation of a neuron in Neural Planner The Artificial Neuron
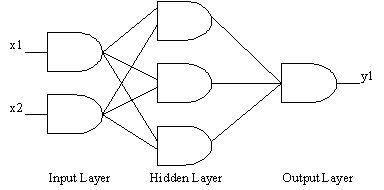
The dendrites are the inputs to the neuron and the axon is the output. The terms dendrites and axons are not usually used with the artificial neuron and they are only included here so that comparisons can be made with real neurons. Each synapse has a weight representing its -connection strength. These weights are modified during the learning process and form the memory of the neural network. The product of the inputs and the weights are added together, a sigmoid function applied and the result appears as an output. Neurons can be seen as very simple devices and only gain their power when they are combined into networks. The diagram shows a three-layer network with two inputs xl and x2 and one output yl.
Three-layer single-output Output Layer Neural networks normally have great potential for parallelism, since the computations of the components are independent of each other. In principle, NNs can compute any computable function, i.e. they can do everything a normal digital computer can do. In practice, NNs are especially useful for mapping problems which are tolerant of some errors, have lots of example data available, but to which hard and fast rules can not easily be applied. In this respect they can be viewed as complementary to knowledge-based systems. Learning Most neural networks have some sort of "training" rule whereby the weights of connections are adjusted on the basis of presented patterns. In other words, neural networks "learn" from examples, just like children learn to recognise dogs from examples of dogs, and exhibit some structural capability for generalisation. Neural networks learn by being presented with training data. There are many learning methods for NN5 by now. Nobody knows exactly how many. New ones (at least variations of existing ones) are invented every week. The main categorisation of these methods is the distinction of supervised from unsupervised learning: In supervised learning, there is a "teacher" who in the learning phase "tells" the net how well it performs ("reinforcement learning") or what the correct behaviour would have been ("fully supervised learning"). In unsupervised learning the net is autonomous: it just looks at the data it is presented with, finds out about some of the properties of the data set and learns to reflect these properties in its output. What exactly these properties are, that the network can learn to recognise, depends on the particular network model and learning method. Many of these learning methods are closely connected with a certain (class of) network topology. Some topologies use feedback where the output of certain neurons is fed back to the input of neurons in an earlier layer. Others only feedforward. Here is a list, just giving some names: 1. UNSUPERVISED LEARNING (i.e. without a "teacher"): 1). Feedback Nets: 1. Additive Grossberg (AG)
2). Feedforward-only Nets: 1. Learning Matrix (LM) 2. SUPERVISED LEARNING (i.e. with a "teacher"): 1). Feedback Nets: 2). Feedforward-only Nets: 1. Perceptron
'Overfltting' (often also called 'overtraining' or 'overlearning~) is the phenomenon that in most cases a network gets worse instead of better after a certain point during training when it is trained to as low errors as possible. This is because such long training may make the network 'memonse' the training patterns, including all of their peculiarities. However, one is usually interested in the generalisation of the network, i.e., the error it exhibits on examples NOT seen during training. Learning the peculiarities of the training set makes the generalisation worse. The network should only learn the general structure of the examples. There are various methods to fight overfitting. The two most important classes of such methods are regularisation methods (such as weight decay) and early stopping. Regularisation methods try to limit the complexity of the network such that it is unable to learn peculiarities. Early stopping aims at stopping the training at the point of optimal generalisation. A description of the early stopping method can for instance be found in section 3.3 of /pub/papers/techreports/1994-21.ps.gz on ftp. ira.uka.de (anonymous ftp).
Introductory Texts 1. Aleksander, I. and Morton, H. (1990). An Introduction to Neural Computing. Chapman and Hall. (ISBN 0-412-37780-2). Comments: "This book seems to be intended for the first year of university education." 2. Beale, R. and Jackson, T. (1990). Neural Computing, an Introduction. Adam Hilger, lOP Publishing Ltd: Bristol. (ISBN 0-85274-262-2). Comments: "It's clearly written. Lots of hints as to how to get the adaptive models covered to work (not always well explained in the original sources). Consistent mathematical terminology. Covers perceptrons, error-backpropagation, Kohonen self-org model, Hopfield type models, ART, and associative memories." 3. Dayhoff J. E. (1990). Neural Network Architectures: An Introduction. Van Nostrand Reinhold: New York. Comments: "Like Wasserman's book, Dayhoff s book is also very easy to understand".
References 1. Neural Networks FAQ from comp.ai.neural-nets newsgroups 2. Introduction to Neural Networks, Phil
Picton 1994, Macmillan Press |