BlueAdmiral.com
|
BlueAdmiral.com |
|
| Modelling Human Problem-Solving |
| Introduction You are familiar with a range of computer software - DP, statistical packages, spreadsheets, etc. These packages handle data, perform arithmetical calculations, retrieve records, etc., but they are not INTELLIGENT. They may be able to perform complex calculations very rapidly (and therefore perform analyses that would take a very long time even with a calculator) but they are not going to discover a new law of physics. A program will follow precisely the sequence of activities laid down by the programmer. For many years people have been trying to make software less dumb and to perform intelligent problem-solving using the same kind of techniques that humans use. This is ARTIFICIAL INTELLIGENCE (AI). The first attempts (1950s) were to recreate the human brain. The idea was that Wit could have a complex interconnected network of artificial neurones than it might be able to duplicate the human brain and learn things. There were (and are) some small scale attempts that were successful at a very basic level (e.g. Perceptron - an elementary visual system that could be taught to recognise a limited range of patterns. However, the human brain contains 10 billion neurones and each may be connected to many others so the total number of pathways is astronomical. The next major approach was to duplicate the human thought processes, looking at human thinking as a complex system of what is basically symbol manipulation. This had some promise since computers can search, compare symbols, etc., which was considered to be the foundation of intelligent problem solving. Again, there was some limited success, the most famous of which was a program called "General Problem Solver" (GPS). GPS sounds very grand but actually it could only work in very restricted situations with clearly defined rules. The central idea was that problem solving is a search through a list of potential solutions. This can involve a lot of unnecessary effort unless there is some guidance to the most likely paths to follow. There needs to be a good search strategy and most are based on heuristic principles. GPS was not much good at real life problems because these do not usually have precise rules. The goal of discovering algorithms which would provide a general framework for problem-solving proved elusive as the more classes of problem a single program could handle, the less was its performance on any particular problem. It became apparent that a more useful approach would be to concentrate on more specialised 'domains' (fields of expertise). In the 1970s, Al moved away from trying to computerise general intelligence and towards a very narrow area of expertise. This is the EXPERT SYSTEM. One of the most important of the early expert systems was MYCIN. This is a program to diagnose bacterial infections of blood and to prescribe the appropriate drug therapy. The idea behind this is that a doctor keys in information that he has obtained from tests on the patient and the program will tell him what organism is causing the infection and what treatment should be given. This is rather like having a tame microbiologist and haematologist sitting beside you, i.e. an expert in a particular field. Hence it is an expert system. The basic idea of an expert system is to deal with a small area of knowledge and encapsulate knowledge in a program which can be accessed by somebody at any time and thus replace a human expert. This is not to say the expert is redundant, simply that his knowledge becomes more widely accessible. Human experts have several disadvantages: 1. scarce So, to set up an expert system you need, not just an expert but one who can explain how he/she works and this is not always easy. An example is: the car starts making a horrible clonking noise and the mechanic says "Big-end going". "How do you know that?" "Because horrible clonking noises like that are nearly always caused by the big-end going." This is built up from many years of experience of hearing different sorts of noises and identifying problems with them. He doesn't have to consider all conceivable solutions but homes in on a correct one in a sort of intuitive, common sense way. Computers require precise instructions and to convert this expert knowledge into a program is a difficult job and is done by a knowledge engineer.
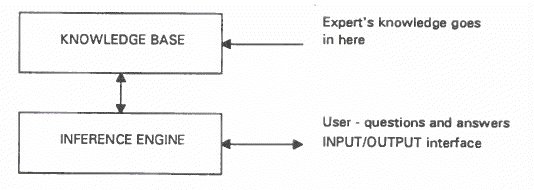
An expert system is a computer program that simulates the reasoning of a human expert in a certain domain. To do this it uses a knowledge base containing facts and rules and some inference procedure for using this knowledge. Basically, the inference engine is a general
purpose reasoning program and the knowledge base provides this
program with the knowledge about which the program will reason.
Fortunately, human experts reason in the same sort of way in different fields so it is possible that the same basic reasoning program can sort Out problems in the fields of, say, car fault-finding and deciding on insurance premiums simply by plugging in a different knowledge base. This allows the development of expert system
"shells" such as CRYSTAL or XiPlus which This is not as easy as it is made to sound. A general purpose inference engine working on a particular structured base may be able to work in several related areas but would not be mucl4 good at particular specific problems in specialised fields, e.g. ES working out a payroll by I acting as expert on the subject of pay regulations would not be much good at working out the structure of chemical compounds - partly because the format of the knowledge base would have to be very different. Comparison with conventional programs (brief- more later)
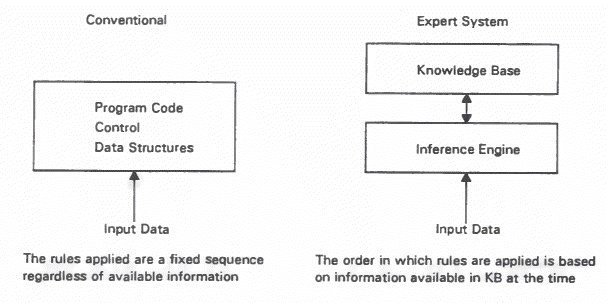
In a rule-based system, knowledge and control are kept separate and knowledge is not represented by subroutines or other parts of program code. The program itself is only an interpreter.
N.B. "Knowledge" is not the same thing as "data" - knowledge implies classification and organisation of facts to provide an understanding of the world which is predictive. Thus, Expert systems differ from 'ordinary' computer programs since, where 'ordinary programs manipulate data, expert systems manipulate knowledge (i.e. data and inferences). Expert systems may use heuristics (see later) to control the way in which they search through the knowledge base or gather information. Although it is possible to write an expert system in 'ordinary' programming languages such as C or even BASIC, specialised languages such as LISP or PROLOG may be particularly suitable.
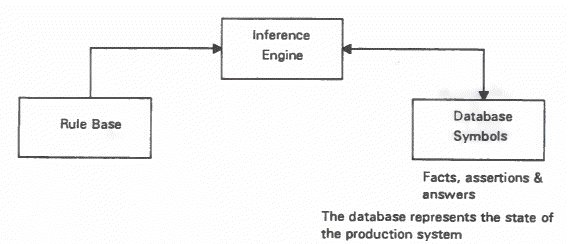
Production System Usual internal organisation of an expert system is based on the production system which consists of three parts: 1. rulebase The production system uses knowledge represented by production rules or if-THEN rules. The inference engine scans the rules until one is found that can be fired. The result of this is to change the state of the database by adding or replacing symbols.
Production Rules Human experts often think in if-THEN patterns. The condition is a test of the current state of the database and the action updates the database in some way. e.g.. IF the time is 5.30 (or whatever) THEN the class is over. This can be made more complicated by using AND and OR connectors. Suppose your car will not start. When you have tried swearing at it and kicking it and it still will not start, you might reason as follows:
Suppose car is not starting and engine is not turning over so clearly starter motor is not working. IF starter motor is not working THEN battery might be flat. There may be other reasons, e.g. the starter motor may be broken so you could add another condition to justify the action part of the rule. iF starter is not working AND headlights are dim THEN battery might be flat. You still cannot be sure conclusion is right because battery connections might be poor so you could add AND battery connection good to LHS.
A Simple Example of a Production System
Exercise Suppose you need to prepare a system for selecting drinks Write rules for distinguishing these 3 drinks - wine, beer, mineral water.
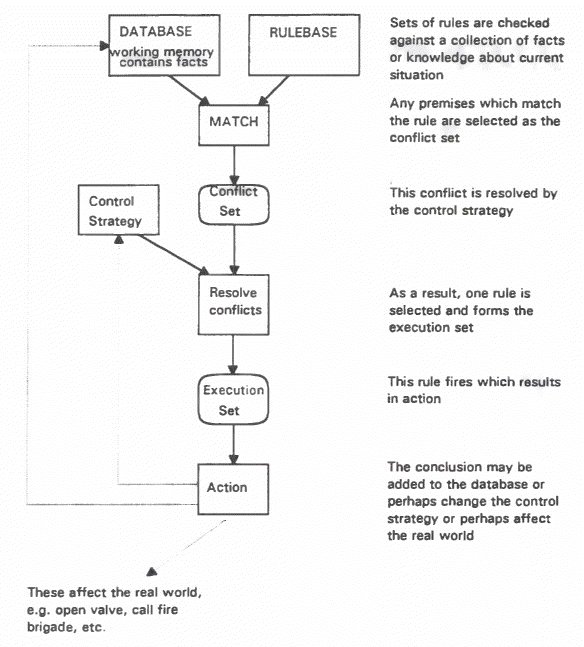
The inference engine would be programmed to operate as follows: 1. Find all production rules whose condition
parts are TRUE. Make these rules applicable. In step 1 all LHS are evaluated as TRUE or FALSE (all parts of AND must be TRUE) Step 2 prevents the addition of information already present. In step 3 one of the applicable rules is fired. Some form of conflict resolution is necessary. The system cannot make any further deductions if no rules are applicable so QUIT. Alternatively, ask for more facts. Step 4 reset applicability and start a new cycle. How would this work in practice? Your answer to the above exercise might be: R1 IF non-alcoholic THEN mineral water Suppose the user enters the following facts: Drink is (alcoholic, made from grapes) (Database contains these facts). In the first cycle, R2 is made applicable and fired. This adds wine to database so the contents of database are now (wine, alcoholic, made from grapes). During the next cycle the inference engine
cannot find a rule to fire so execution is finished. The system's
answer is defined to be last entry made to the database. Conflict Resolution What other strategies could be used? If data added to database is tagged with time then it could decide to fire rules which use more recent data rather than those which use data which has been loitering for some time. This way, the "leading edge" of computation is followed rather than doubling back to look at old data. It may need to double back if current line
of reasoning fails. i.e. IF A AND B AND C then S would be preferred to If A then S. The former takes into account more of the current data. 4. Symbols stored in the database are ordered and the rule which matches symbols with the highest priority is fired. There is no reason why all strategies could not be used in a particular production rule language. Summary so far - Control Cycle
Control Strategies
The control strategy for the search procedure is the order in which rules are scanned for triggering. It is necessary to decide on the direction of search and the search method. These procedures are normally part of the inference engine. The knowledge engineer has only limited control of this procedure. Controlling the behavior of rule-based systems poses various problems. There are two general approaches - global and local: Global: In this approach (termed domain free) the strategy employed does not use domain knowledge to any extent. Local: In this approach (domain dependent) special rules are required which use the domain knowledge to reason about control. At the global level of control, production rules can be driven forward or backward.
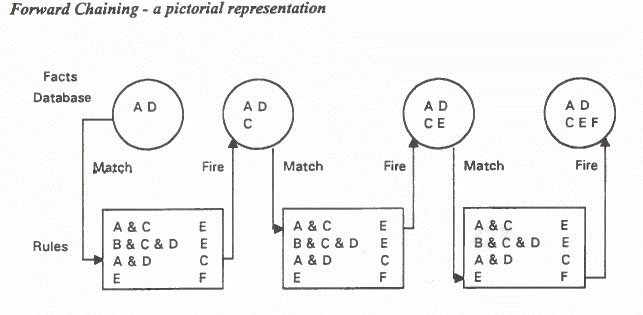
Forward chaining Gather information and try to draw conclusions e.g.. the car will not start problem - collect the symptoms and try to decide what is wrong. Consider these rules - 1. IF A AND C then E The initial content of database is (A,D) This is a natural way of reasoning for humans.
e.g.: in selecting a suitable insurance policy you could start by collecting data regarding age, sex., family, salary etc. and then match these data with best policies. This approach also known as: In CRYSTAL you could implement this by having a rule for getting the data via the DISPLAY FORM, MENU QUESTION etc. followed by rules for detecting which conclusion is best. This is particularly applicable when you do not know what the main conclusions will I be. The above system seems to work satisfactorily, zeroing in on the fact that F existed. However, a real expert system would not just have 4 rules, it might have thousands. If you used a system that large just to find out about F, many rules would be executed that had nothing to do with F because it is likely that database would have facts other than A & D to start with (M N 0 P Q etc. perhaps). A large number of inference chains and situations could be derived that were valid, but not related to F. Using forward chaining to infer one particular fact could be a waste of time and money. Backward chaining might be more effective
since the system starts with what it wants to prove I and only
executes rules that are relevant to establishing it. Backward chaining
Here we work the other way round. Start from a goal (or expectation or hypothesis) and look for evidence that supports or contradicts this. e.g.. if you think car will not start because your battery is flat, you switch on headlamps to see if they are dim. Backward chaining reflects certain types of expert thought e.g. if a doctor suspects that his patient has a certain disease he will perform tests to confirm it. If his suspicion was correct, a lot of time and effort can be saved compared with performing lots of different tests and then trying to deduce what the disease is. Using same example as before. Rule 1 IF A and C THEN E The Database contains (A D) The goal is to show that F is true. Check database - F is not present. So search RHS of rules for F - R4 Now we know that in order to establish F we must first establish E. Check database - E not present Check the RHS of rules for E R1 &R2 Conflict resolution - choose R1 Now we have to deduce that A and C are TRUE Since A & D are in DB we can fire R3 which adds C to DB. So DB now contains (C AD) Go back to Rl since now have A & C TRUE Fire Ri. DB now contains (E C AD) Now fire R4 so DB contains (F E C AD) Answer F To implement this you must start by defining
your conclusion then enter all conditions and alternatives that
satisfy it. The user could be asked to select their own goal (e.g..
insurance policy) using the MENU QUESTION. CRYSTAL would then
check that conclusion. Backward chaining has some advantages: 1. It only asks questions that it needs
to know to establish the goal. e.g.. in the example above the system could tell user: I am trying to use R1 There is no need to use just one of these techniques. In fact mixture of two approaches is often a good idea. e.g.. we might wish to monitor data and conditions until a particular set of circumstances arises and then try out various conclusions or possibilities to analyse that situation. The first part is data driven and the second part is conclusion driven. Alternatively, work with backward chaining
while making progress and then switch to forward chaining when
difficulties arise (e.g.: PROSPECTOR does this). Backward and forward chaining of production rules have been used in the majority of expert systems so far produced. However, in a large system, there may be so many rules that the number of program statements becomes difficult to manage. It has been suggested that such a system is incapable, with present technology, of representing more than 10,000 rules. This would be ample for most small-scale applications but would restrict the ability to represent many areas of human expertise. As a rough guide, it has been estimated that a chess grandmaster would have a store of some 50,000 rules. Heuristics If you are playing chess, you do not consider all possible moves when it is your turn. The number of moves would be too large to manage, especially as you would have to consider the consequences of each move. Each move would involve assessing the average of seven counter-moves, each of which may lead to another seven counter-moves and so on. This is known as a combinatorial explosion. In practice, a good player can classify
good moves and learn how to win - they recognise patterns and
develop strategies. If a mouse is placed at the start of a maze, there are several ways for it to proceed in order to find the cheese. (a) wander randomly hoping that sooner or later it will find the cheese. There is no guarantee of success. (b) search systematically through every route. This will work but could take a long time I It might starve before getting to cheese! This is wasteful because several routes have paths in common. (c) Keep to the wall on the right and follow
it through. This will work but again it could take a long time. Heuristics are not usually proven but are learnt from experience and work adequately. Many real-life problems resemble the maze - there are several ways of tackling them. Some methods are guaranteed to succeed but may be long-winded and therefore inefficient. An expert evolves a strategy for solving a problem. Heuristics can be programmed into computer systems to help with the solution to complex problems. |