| In the previous section we introduced the role
of the operating system. We have examined the early use of job
card control, moving on to the introduction of spooling systems
that allowed the sharing of a processor between programs and devices.
We identified the need for improved CPU utilisation. We described
how the operating system supports the sharing and controlling
of the computer system's resources. A range of processing techniques
were introduced, including timesharing, multiprogramming, concurrent
processing and batch processing. We identified four key elements
of the general model of an operating system, namely the Device
Manager, Process Manager, File Manager and the Memory Manager.
We finally identified the need for each manager to work together
in support of the overall computer system, whilst maintaining
individual responsibility for each of the resources under their
control.
The role of the process manager
As already briefly discussed the Process Manager (PM) is responsible
for making the best use of the CPU (or CPUs). The PM will take
charge of how a job is allocated processing time, and will continue
to monitor the job whilst it is being processed. As soon as the
job no longer requires processing (at a particular step), the
PM will direct the job to the next job state, and then reclaim
the CPU ready for the designated job request. Each of the operating
system's managers (FM, PM, DM, MM) will have their own responsibilities,
with their own policies in place to meet those responsibilities.
The PM will have such a policy in place, and whilst we consider
'single-user' processing (a single job using a single processor)
the policy remains relatively simple. This policy will take on
far more complexity when dealing with multi-user (multi-programming)
systems. The policy must have a plan that permits a single CPU
to allocate and de-allocate the CPU between the users and the
jobs.
Multi-user/multiprogramming systems
Multiprogramming systems appear to allow several programs to be
active at the same time. If a single processor is used, the CPU
will work on only one program at any one time, according to the
priorities and actual requirements. In other words, programs (or
jobs) take it in turns, one job uses the resource for a while,
while other jobs wait in a holding area. If there is only one
processor, it is not physically possible for another job to use
the same processor simultaneously. But many jobs could have been
released, and therefore be active in one time-frame. One job could
be using the CPU, another could be writing a record to a file,
another could be writing a file to a printer. The users all have
the illusion that the system is working solely on their job. A
benefit of multiprogramming is the better use of available resources.
Multiprogramming or parallel processing
Multiprogramming typically has a single processor. That processor
will be event driven - the sharing of the computer's resources
will take place when an event happens. Each event will be recognized
by an interrupt. An interrupt is a 'condition' that is met and
subsequently stops 'normal' processing temporarily. Once the interrupt
is received the operating systems will advise the relevant manager
to reclaim their resource for future use. Other jobs can now use
the resource. Parallel Processing will have a number of processors
all managed by the PM. It will permit many jobs to run 'simultaneously',
and in some cases many parts of one job (program) to run simultaneously.
The single processor with multiple-users (multiprogramming)
Let's imagine that you are the CPU - as such you are responsible
for processing all the program jobs you receive. Under the supervision
of the operating-system's PM two or more programs (jobs) can be
loaded into your main memory. Following some established policy
(with stated priorities), the CPU will execute a set of program
instructions from the first program - Job 1. When the operating
system receives an I/O interruption from Job 1, it will turn its
attention to processing a set of instructions from Job2, until
another interrupt is received. The CPU can now complete the next
set of instructions (steps) in Job 1 and so on, until all steps
in all programs have been executed and completed.
A model of multiprogramming
Consider the following set of instructions for a simple DIY task.
Figure 1: Book-case assembly kit
Instructions: You are required to read the
assembly instruction, gather the tools required for the job and
then get the work force ready. You will need to join part A to
part B, giving you a new part X You must use 2cm brass screws.
Next you will need to join part C to part D giving the new part
Y You are then required to join part X to part Y, this will make
the new part Z Finally you will be required to join parts E and
F to part Z Like a good workman, when you have finished you should
return the tools to their rightful place and dismiss your workforce.
Both the tools and the workforce will be ready to work on future
jobs.
The process schedule might look as follows
in example 1.
Example. 1
Process Schedule: Job1
Step-1 Locate job instructions (MM, DM)
Step-2 Read job instructions (FM)
Step-3 Assign device - tools (DM)
Step-4 Assign CPU - Join Part A to Part B with 2 inch screws;
this becomes Part X. (PM, FM)
Step-5 Join Part C to Part D, becomes Part Y (PM, FM)
Step-6 Join Part X to Part Y, becomes Part Z (PM, FM)
Step-7 Join Part E to Part Z, position 1 (PM)
Step-S Join Part D to Part Z, position 2 (PM)
Job terminated successfully
Step-9 Reclaim resources (DM)
This process schedule allows Job 1 to work
through each step until termination of the job. This pattern is
typical of a single user/single processor system. However, now
lets consider what would happen if we had many users. Each job
would be submitted and then await processing. The processor could
select a job based on some form of priority basis. The first job
would remain active until an interrupt is received. At this point
the PM would review all jobs awaiting processing and then assign
the CPU to the job with the highest priority.
Let us re-examine the task required, reviewing
the process schedule shown as Example 1. We begin to assemble
the book-case when suddenly a friend cries out in pain. In effect,
an 'interrupt' message has been sent. The receipt of an interrupt
message allows the PM to hold processing of the current task.
The PM switches the processor to the higher priority task. When
this task has completed the PM will reclaim the processor and
then re-allocate it to the suspended job. Your friend still requires
your help. This immediately takes priority over the job in hand.
However you make a mental note of your last working position prior
to putting the task on hold. You are now ready for the second
task - apply first aid to your friend. Making a mental note of
your latest position can be likened to applying a context switch
prior to the temporary suspension of the first task. The context
switch will used as a marker so that you can return to processing
when ready.
Jobs verses processes
With a single user system the processor is only busy when running
a job, otherwise the processor is idle. In this case the process
management is relatively straightforward, and as such there is
no distinction made between the job scheduler and the process
scheduler. All the resources are dedicated to the one job only.
However, within a multiprogramming environment the PM has to work
much harder. The PM will attempt to allow each job a fair share
of the processor.
The PM will allocate the processor to the
current job (for example the job with the highest priority), and
will then de-allocate resources when appropriate. Special care
has to be taken when de-allocating a processor from a job. There
must be a facility in place to allow the processor to return to
the last processing position in a job when the processor becomes
available.
We already know that:
o one job = one program (or one unit of
work)
o process = a working step in a program
o the CPU can only physically process one of these steps at any
one time.
With a multiprocessing system, a process
may use all (or any) of the resources available on the computer.
A process may share the use of a resource within one time span.
All of these tasks can only be made possible through the use of
scheduling. To facilitate this the PM has two sub-managers, or
if you like two supervisors, namely the Job Scheduler (JS) and
the Process Scheduler (PS).
Job scheduler
The Job Scheduler is responsible for selecting the job from the
queue and placing the job in the processing queue. The IS will
attempt to sequence the jobs in such a way that all available
jobs have maximum use of available resources - in other words
to minimize the idle time of resources. The JS will try to balance
the load between the CPU and the I/O.
The JS is a higher level scheduler and will
be the first to meet a job. It aims to select jobs from incoming
queues and place them in processing queues according to job characteristics.
It will place the jobs in a sequence that will optimize the computer's
resources. The JS will also attempt to balance the jobs according
to their demands upon CPU and I/O.
Process Scheduler
The JS will have placed the complete job onto a 'ready' processing
queue. The Process Scheduler is responsible for assigning CPU
to execute processes. It has to decide which processes are assigned
CPU, when, and for how long. It also decides when a job should
be interrupted, which queue a job is moved to or from, and when
a job is finished. The PS is a low-level scheduler. It undertakes
a critical role especially when dealing with a number of jobs.
Most programs will follow the trend of carrying
out some processing and then some I/O. The PS will attempt to
shift the job in and out of the resources according to the job
characteristics. Figure 2 shows this process in diagrammatic form.
It shows that jobs are released into a holding area before execution.
Figure 2.- A job state diagram
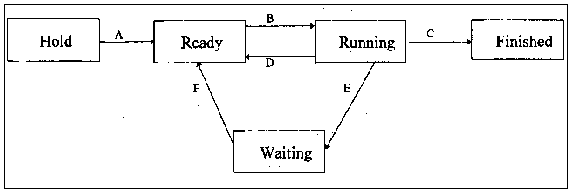
Key:
A Hold > Ready
The JS will initiate release according to the pre-defined policy.
The JS will check for enough memory and will check that the required
devices are available.
B Ready > Run
The PS takes over and runs according to pre-defined algorithms,
e.g., priority scheduling, SIN, etc..
D Running > Ready
PS will move job back to ready state according to for example,
reaching end time-slice, or reading an interrupt.
E Running >Waiting
The PS schedule moves jobs here based on say an I/O request from
a job, for example read/write or fetching a page.
F Waiting >Ready
The PS waits for a signal from the I/O device manager stating
I/O request has been met. The PS moves the job back to ready state.
C Running >Finished
When job has finished running the PS will move the job to finished
state - this will happen for both successful finish and unsuccessful
finish.
Process control block (PCB)
Each process is represented by a data structure called a PCB.
The PCB acts like a traveller's passport. The PCB will contain
basic information about the job, such as what the process is,
how much of process has been completed, where it is stored, and
so on. The PCB is created when a job is accepted by the PS. The
PCB will be updated throughout the job's duration. Figure 3 shows
the information contained in a typical PCB. Each PCB will be unique,
referring to a specific process within that job.
Process Identification
Process State
Process state word
Register contents
Main memory
Resources
Process priority
Accounting
Figure 3: A typical PCB
o Process ID will be unique identifier,
based on user's identification, and IS supplied reference point.
o Gives position in state diagram. Also
gives resources responsible for status.
o Will be blank if job running, else will
give position on state diagram.
o Will contain value if job has been interrupted,
and is awaiting further instruction.
o Will contain address where job is stored.
o Gives details of all resources allocated
to job (including relevant resource address)
o Gives details of any priority of any algorithm
that may be use.
o Used where accounting, monitoring or charging
implemented, e.g., for use of CPU or I/O/
Queues
Only one process can use the CPU at any one time. All other processes
must be put in a queue. Queues are basically linked lists of PCBs.
The PCBs will be linked together according to their 'wait' reason.
Each process will be waiting for a particular resource, for example
there will be queues for the line-printer, page-interrupt, printer
I/O, and so on. The PS will manage the queues 'and will award
the PCB a visa to enable processing to continue on their job -
hence the comparison with a traveller's passport.
Schedule policies
The PS will have a policy to best allocate CPU time and other
resources. In practice many policies will have conflicting aims,
such as trying to achieve:
o fairness fair use of CPU for all users.
o efficiency best use of available resources.
o response time try not to keep users waiting.
o turnaround - ensure minimum job turnaround.
o throughput - get as many jobs through as possible.
Pre-emption scheduling policy
This is a policy based on pre-determined policies; it interrupts
the processing of a job and then gives the CPU to the next job.
This policy is mainly used in time-sharing environments. Most
PS will not run a job through to completion without interruption.
Jobs will be interrupted to allow other jobs to share resources.
Round Robin
This is a form of pre-emptive process scheduling - it is mainly
used in interactive systems. Time-sharing prevents an individual
job from monopolizing the CPU. Each process is assigned a fixed
time-slice (also known as a time quantum). A time quantum is set,
and can for example vary in duration from 100 milliseconds through
to 3+ seconds. If a job process has not finished processing it
is pre-empted and placed into a waiting queue. Typical allocation
of jobs could be:
o abcabcabcabc.... (where job a runs, then
b, then c, etc., each at same time slice).
This also gives job priority, we could quite
easily change sequence to for example:
o abccabccabccabcc.... (where job a runs,
then b, then c, then c, then a, etc.).
The first example shows that all jobs have
equal priority, but the second example gives priority to job c.
Priority scheduling
Round Robin may assume all processes are equally important, but
this is not normally the case. Priority scheduling is not pre-emptive,
and is more commonly used in batch processing. Unlike Round Robin
all users do not get fair slices of CPU time. Some processes will
get 'better' treatment. Priorities can be applied to each job
according to their running urgency over other jobs. Higher priority
jobs will retain CPU until processing is finished or a job is
interrupted with an I/O request. The next highest priority job
will then retain CPU resource. System administration or operation
can apply priorities to jobs dependent on their importance. Priorities
can be applied via the PM based on job characteristics such as
memory requirements, type of peripheral devices, total CPU time
required and time already spent on the system. Priority Scheduling
will assign a priority to a process. Time is then allocated to
the highest allocated process. If equal opportunities exist then
a first come, first served approach is adopted.
Multiple queues
These are not really separate scheduling algorithms, rather they
work in conjunction with other schemes. Basically a queue will
have a predetermined scheme allocating a special treatment to
the jobs in the queue. Within each queue each job will be served
on a first come, first served basis. Several queues of processes
can be set up. For example, Qa gets one time slot, Qb and Qc get
two time slots and Qd gets 4 time slots. Multiple queues are another
form of prioritizing and can lead to more efficient use of the
system. Problems could arise whereby jobs were continually submitted
to the high priority queue - the jobs in the lowest priority queue
risk not being executed. To overcome this, 'ageing' is used to
ensure that jobs that have been in the system for a long time
in a low priority queue will eventually be executed to completion.
The system keeps track of each job's running time (including waiting
time). When it reaches a predetermined waiting time the job is
moved to a higher priority queue.
Lottery scheduling
This uses a lottery of CPU usage where each process is given a
CPU ticket. A ticket draw takes place and determines the next
process to run. Processes may receive more than one ticket.
Two level scheduling
Use of virtual memory can sometimes cause scheduling problems
due to the imbalance of the speed of the request and the access
to virtual memory. It is not always possible to optimize for fast
access. A solution of this is to use two schedules:
1. a high level scheduler to swap jobs to
and from disk
2. a low level scheduler to swap to and from RAM.
Interrupt handling
This is the program that controls what action should be taken
by the operating system when a sequence of events are interrupted.
There are two types of interrupt:-
1. hardware - from external devices such
as printers, tape-drives etc..
2. software - according to CPU management, or, perhaps due to
an illegal job instruction such as an arithmetic divide by zero
error.
An interrupt may also occur when attempting
to access non-existent data or for example protected data. A typical
interrupt procedure might be as follows:
1. Stop current task.
2. The interrupt is described and stored, it may be passed on
to the user as a formal error message - apply context switch.
3. Stack the status - counter values and resister contents are
noted.
4. Run interrupt process to completion - the job is halted.
5. Recover status -allocated resources are released and the job
exits the system.
6. Restart current task - the processor resumes normal operation.
Synchronization
This is essentially used in an attempt to address problems caused
when the processor cannot service all the processes of the system,
especially when many processes are fighting to use very few resources.
Processes compete for the same limited resources. To assist fairness
of use and balance of resources we need to synchronize access.
Without synchronization two extreme conditions can occur - deadlock
and starvation.
Deadlock
This can be described as a state where at least two processes
are waiting for the resources that are held by each other, and
so are unavailable. Both processes are unable to continue without
requesting the necessary resources, and the resources already
allocated to them cannot be released, and thus having an impact
on the successful execution of the other process. A deadlock simply
locks up a subset of processes on a system, and in extreme cases
may go on to lock up the entire system. An error condition will
occur whereby processing cannot continue due to the fact that
two processes are waiting for an action from each other.
For example.
o Process A has resource 1, and wants resource 2
o Process B has resource 2, and wants resource 1
Neither process will release the other resource.
This state can lead to starvation - neither process receives what
they really need!
This will happen when the execution of a process is indefinitely
postponed or delayed. The system may not be affected, but the
processes most certainly will.
Race conditions
Here a problem occurs when two processes try to access the same
resource at the same time. A race occurs when scheduling of both
processes are critical. It may be for example, critical that one
process executes just before another process. Perhaps a variation
in the order of their processing could result in totally different
computation and subsequently different results. The system itself,
not the running of the processes, will be affected but obviously
an incorrect running order will produce inaccurate results. A
solution is to use a procedure called mutual exclusion.
Mutual exclusion (mutex)
This is a condition that occurs when only one process may use
a shared resource at a set time to ensure correct operation and
subsequent correct results. Here we have to consider the integrity
of the data. Perhaps updates to one set of data are being carried
out by two different processes. It is critical that process A
has access to the data first, so we must make sure that process
B cannot use data resource until it has finished processing. The
first process sets mutex, and so 'locks-out' the second process.
Deadlock handling
There are four possible actions:
o Prevention - is the key - you should try
to eliminate the conditions that could lead to a deadlock in the
first place.
o Avoidance - try to stay in a safe area of a condition . Do not
allocate a resource if it takes you to an unsafe area.
o Detection - When a deadlock is detected, you should sequentially
remove the allocated resources until the deadlock is removed.
o Recovery - Kill off jobs until the deadlock is resolved.
Four conditions of deadlock
1.Mutual exclusion
(1st condition) Two people meet on the stairs between landings
- they cannot pass because the steps only hold one person at any
one time. Mutual exclusion will allow one person (a process) to
access the step (a resource).
2.Resource holding
(2nd condition) Two people meet on the stairs and each person
holds their 'own' ground. They will wait until the other person
retreats. This demonstrates resources holding (holding on to the
step) rather than resource sharing.
3.No pre-emption
(3rd condition) Each step was allocated to a climber and a descended
only as long as they required the step (the resource). When the
climber and the descended meet in the middle of the stairs there
is no waiting area - this lack of waiting area (a temporary storage
area) leads to deadlock.
4.Circular wait
(4th condition) Here each person (the process) is 'waiting' for
another process to voluntarily release the step (the resource)
so that at least one person (a process) will be able to continue,
and eventually arrive at the top of the stairs. All four conditions
are required before deadlock occurs. Whilst all conditions are
there deadlock will result. If we can prevent the condition happening
then deadlock will be avoided. This is obviously not such an easy
task. The operating system will however, attempt to:
o prevent conditions from occurring in the
first place
o avoid deadlock when it becomes a problem
o detect deadlock and then attempt to recover from it.
Summary
This section has examined the role of the Process Manager within
the general model of an operating system. We have described the
role of the PM and how it uses a range of policies to carryout
its role. We have explored a number of differences between multiprogramming
and parallel processing. Also, we have examined the differences
between multiuser and single user systems. We have identified
the supporting roles of the job and the process schedulers, also
covering the role of the Process Control Block and how it is used
within job queues. We have looked at a range of processing policies
used in order to achieve optimum processing using the available
resources. Finally, we have identified a common problem experienced
when sharing resources. In particular we have looked at the four
stages of deadlock and how they can be overcome.
|