BlueAdmiral.com
|
BlueAdmiral.com |
|
| Distributed Databases | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
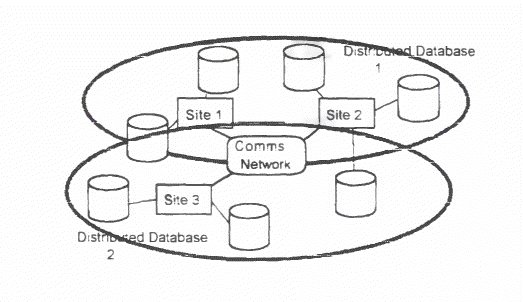
| Introduction Distributed Databases The figure below shows an organisation split across three sites, which has two distributed databases.
Distributed databases are useful. as organisations are frequently physically and logically distributed. Also, local databases may already exist which can be amalgamated. To the user, a distributed database should not be distinguishable from a non-distributed database. The database should exhibit location transparency, fragmentation transparency and replication transparency.
Location transparency means that the user should not be concerned with where the data is physically stored. The data should appear to the user as if it is all held at the terminal on which they are working. Fragmentation transparency means that the user should be unaware how the tables or rows are broken down for storage The data should be reassembled for the user into the known tables and rows without them being aware that it is happening. Replication transparency means that the user should be unaware that multiple copies of data exist. These may' have been created for efficiency reasons, but will require mechanisms to ensure that all copies are updated when changes take place on the data. The user should not be required to make these changes to multiple copies themselves. There are other requirements and benefits. Each site should have local autonomy and ownership of data. and should avoid reliance on a central site, if systems at other sites go down, the autonomous sites can still operate independently Distributed query processing will be required, alone with distributed transaction management. Again, ideally, the distributed database will exhibit independence from hardware, operating system, network and even the database management system at each site. A distributed database can offer modular growth, local control, faster response for local queries and greater insulation from network failure. Problems can arise if data is poorly distributed with poor response times. Software cost and complexity can be greater with a processing overhead caused by the need to co-ordinate sites and a threat to data integrity if this co-ordination is not achieved. Possible strategies to create fragments for data distribution are o replication o horizontal partitioning o vertical partitioning Replication (copying of data to necessary sites) is not quite in the spirit of distributed databases. It increases storage requirements and causes difficulty in keeping all copies updated in parallel. Therefore, it is useful only for read-only applications such as lookup tables which are relatively stable.
Horizontal partitioning allows those rows of a table relevant to a par-ticular site to be held locally. For example, the rows for customers for each branch may' be held at the relevant branch, despite being part of a single logical CUSTOMER table If head office try to access all the rows of table it will be reassembled. Vertical partitioning allows those columns of a table relevant to a particular site to be held locally. For example, the product table may have: o design specific columns such as designer and draughtsman held by the Design department o production specific columns such as machine tool settings and batch sizes held by the Production department o manufactured cost and sales price columns held by the Sales department. These distributed columns form a single logical table.
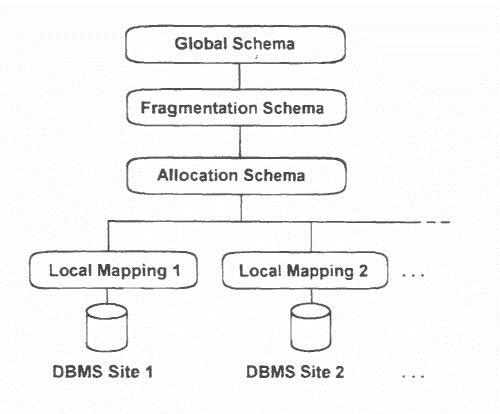
A Distributed DB Design Approach There are several architectures for the design of distributed databases. Only one will be covered here which is attributed to Ceri and Pelagatti. The diagram summarises the approach in which the Global Schema can be compared to the Conceptual Schema of the 3-level Architecture for a non-distributed database. The fragmentation schema details the fragments into which the Global Schema tables are broken by horizontal or vertical partitioning. Ceri and Pelagatti do not allow overlapping fragments in the fragmentation schema. These fragments are then allocated to physical locations or sites in the allocation schema. Finally, the fragments allocated to a particular site may be rearranged to make a consistent database via a local mapping schema.
Example For a scenario where details of building fires are to be recorded for Britain. the entities FIRE & INSURER has the following attributes.
Three locations are to co-operate in a distributed database. They are London. Manchester and Edinburgh. Each city is to store all rows relating to themselves. All cases of arson are also to be stored in London. All insurer details are to be stored in London. All insurer details are to be stored in London, as are any fires which are neither marked for Manchester or Edinburgh Two views are also required named costly and notable. Costly is where damages are 2reater than £100,000. Notable damages are costly damages which are arson after 1992. Global Schema
No overlap is allowed so there may be mans fragments
Local Mapping Schema London needs the arson fragments recombined to allow the views to be applied. arson = others_a UNION edin_a UNION man_a which could be implemented as a single base table. arson
Two Phase Commit It is necessary for distributed databases to implement a "two-phase commit", to avoid updates which affect more than one site making the database inconsistent when the update succeeds at one site and fa!ls at another. In other words, all linked updates must succeed or all must be rolled hack. For a two-phase commit, there must be a co-ordinator (which may be the originator of the transaction). First, the co-ordinator instructs the site to get prepared either to com-mit or roll back. This means that everything necessary must be written to physical storage, (not buffer) so that whatever happens it will event-ually be possible to go either way. When all sites have done this, they report "OK" or "NOT OK" to the co-ordinator. Then, when the co-ordinator has received all replies, it writes an entry to its own physical log (not buffer), again, so that no matter what happens, it can recover. If all replies were "OK", the decision is "Commit", if any were "NOT OK", then the decision is "Rollback". The Co-ordinator then passes this decision to all sites which must carry it out.
Time-stamping An alternative to locking as a means of controlling concurrency in a distributed database is time-stamping. The timestamp is globally unique which usually consists of the clock time when the transaction occurred and the site identification. Thus, two events will always have a unique timestamp no matter where they take place. The timestamp will ensure that time-stamps will always be processed in serial order. This avoids the use of locks arid therefore deadlocks. Every row in the database will carry the timestamp of the last transac-tion to update it. If a new transaction with an earlier timestamp at-tempts an update then it is assigned a new timestamp and restarted. This means that the transaction cannot process a row' until its time-stamp is later than that carried by the row and so it cannot interfere with the action of another transaction. Locking is avoided with time-stamping and therefore deadlock and the need for deadlock detection or recovery are also avoided. Unfortu-nately, the method is cautious and a transaction may be restarted even though there is no conflict with other transactions.
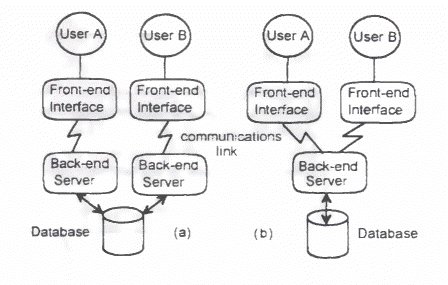
Client Server Architecture A distributed database will employ some
form of client-server archi-tecture. Two possible architectures
are shown in here. The general as-sumption is that a DBMS instance
requires data from the logical database and so becomes a client
requiring a service. The DBMS in-stance which can provide this
data will act as a server to provide the data. Full details of
the client server approach will not be given here. but the following
diagrams show two possibilities for this arrangement
This is essential in order to ensure that queries do not take longer than necessary. A Query over the distributed database could take hours if large volumes of data were moved across the network. The underlying principle has to be that the number of rows and columns in a relational database must be reduced as far as possible before transmission to another site. For example, one site (Q) may request data which is to be obtained b~' a JOIN between tables from two different sites (X & Y). Assume that the query uses a WHERE clause to reduce the rows dis-played to perhaps 10. If each of the tables at X & Y have 1,000 rows the manner in which the query is processed is critical. lithe distributed DBMS carries out an unconstrained JOIN, or Cartesian product, at either site X or Y where the data is held this would result in 1,000,000 rows being transferred to the receiving site, site Q. 1f however, the WHERE clause was used first the transfer could be reduced to perhaps 10 rows at each transfer.
Update Propagation Sometimes data will need to be replicated within a distributed database. Benefits of speed resulting from the data being stored locally can result from this strategy. The problem arises that any update must take effect on all copies of the data without exception. This may be prevented if the network fails at the time of an update and there will then be incon-sistency and the data integrity of the database is compromised. A common solution to the problem is the "primary copy" scheme, where one copy is designated primary and all others secondary. Up-dates are considered complete as soon as the primary copy has been up-dated. It is then the responsibility of the site holding the primary copy to ensure that the update is propagated to the secondary copies.
Distributed Databases with ORACLE ORACLE Versions 5 & 6 allow queries which access data from mul-tiple machines, but do not allow updates to do this. These updates must be individually written and must allow for partial update failures. This involves implementing two-phase commit. Version 7 has the facil-ity to perform two-phase commits itself.. Distributed, queries in ORACLE use the database link facilities. To create a database link while connected to another database use the SQL*Plus command: CREATE DATABASE LINK ealing To access the table students specify the link name after the table name. SELECT * FROM students@ea1ing; A database link restricts access to the privileges granted to the user and password used in the link. The DBA can make a public link which would probably be restricted to select privileges only. By using a synonym the link can be hidden
from the user so that students@ealing simply became students for
example. Another approach to this problem would be to crate a
view on the link table thus also hid-ing the link name. A Distributed DBMS Architecture A distributed DBMS must co-ordinate access to data at the various nodes. Each node must be able to operate with an independent DBMS for local queries and updates on local data, but additional requirements exist for processes which involve data from other nodes. The require-ments are: 1. To determine the location of required
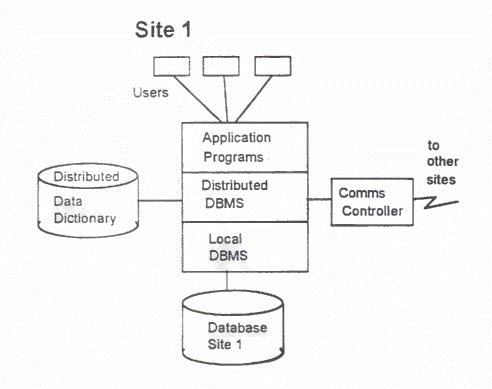
data. In ORACLE7 the first of these issues has been avoided by requiring the code of a transaction to specify explicitly where the data is to be found. It is obviously preferable to allow transactions to be written with reference purely to the global schema and not to be required to supply location details. One architecture for distributed databases treats each site as equally important and therefore an exact copy of the Distributed DBMS software is installed at each site.
Each site has an ordinary DBMS which operates as a local DBMS on the local database for local transactions. Users access this data either directly through the DBMS or through the applications programs. However, if this is to be a distributed database, then some required data may be at other sites, so the location of the data must be determined and decisions made about how to go about retrieving the data etc. This is achieved by routing all requests through a distributed DBMS which uses a distributed data dictionary to find the location of data. Local transactions are passed to the local DBMS. Global transactions split Into requests for data from each site where required data is held and each of these split transactions becomes a local transaction for each particular site. As each site needs to know the location of all data on the distributed database, the distributed data dictionary will be a complete replicated copy at each site. A centralised data dictionary would be possible, but would be highly susceptible to failure and would involve network traffic to access the dictionary for even local data access unless replicated local data dictionaries were held. In a homogeneous distributed database the same DBMS product will be running at each site. This is obviously the easiest arrangement. How-ever, hetero2eneous distributed databases are possible, usually with li-mited capability, where different DBMSs run at the different sites. Usually the DBMSs will need to share the same architecture, for example they will all need to be relational DBMSs (RDBMSs). In a heterogeneous distributed database it will be necessary for the DBMS to translate the request from one site into a correct request for another site which is running a different DBMS product and may have a different query language. SQL is useful here as it is a standard interface, but even with SQL there are variations. Some features which exist in one dialect of SQL do not exist in another. Some identical SQL statements may even execute differently in different RDBMSs. There are frequent-ly differences in areas such as the function names and the level of implementation of the standard. It may therefore be necessary to provide a gateway to provide translation between products. To allow interoperability between DBMSs an effective gateway might have to provide the following: 1. protocols for exchan2e of information,
that is, SQL statements and resulting data. |